Hope, Jonathan, and Michael
Witmore. "The Very Large Textual Object: A Prosthetic Reading of Shakespeare".
Early Modern Literary Studies 9.3 / Special Issue 12 (January, 2004):
6.1-36<URL: http://purl.oclc.org/emls/09-3/hopewhit.htm>.
Wond'rous machine, to thee the warbling lute,
Tho' used to conquest, must be forced to yield,
With thee unable to dispute
(Nicholas Brady, set by Henry Purcell, Ode For St Cecilia's
Day 1692)
Ways of Reading
Those of us who have been trained in the western literary tradition are
used to reading literary texts in particular ways (linearly, at least initially),
and for particular things (somewhat vaguely, but recognisably termed 'themes'
or 'repeated ideas' or perhaps 'abouts' - as in 'Othello is about jealousy').
Our training teaches us to search for words or verbal patterns which are relatively
rare instead of virtually omnipresent--such rarity or distinction being a likely
indicator of what the text is really 'about.' Thus we can recognise repeated
references to 'hands' in Macbeth (though in fact the words 'hand' and
'hands' appear only 35 times in a 2,108 line play) and then link these repetitions
to what the play is 'about': guilt and action.
Judging by the amount of literary criticism published, it seems clear that
this is an effective, or at least very productive, technique of reading.
It is said, for example, that there are more doctoral dissertations about
Hamlet than there are names in the Warsaw telephone book. Thus the
pre-occupation with methodology in what Dilthey called the Geisteswissenschaften
: the relative infrequency of the salient items we select in order to understand
or interpret a text means that other readings (built on other groupings of
salient items) will always be possible, and that it will be difficult, if
not impossible, to say that one reading is preferable to another given the
quantity of empirical evidence. For some critics, this freedom from quantitative
falsification in literary studies has its own value, ensuring an ongoing flexibility
in interpretation and the continuing relevance of particularly 'suggestive'
texts that are capable of supporting many different readings.
We may read texts in this way because we are cognitively biased towards
the unique in our experience. Absent a cognitive theory of reading, it is
reasonable to assume that we begin filtering potentially significant elements
of a text as we begin to have ideas about what they mean. Such filtering,
whether hardwired or prescribed by convention, allows us to pass over certain
items so that we can concentrate on what seems salient. There is the old
saying that, when looking at a wood, we instantly notice the three oaks, randomly
dispersed, but we tend not to pay much attention to the thousand birches all
around them.
In addition to this movement towards saliency, human reading is characterized
by a certain linearity: we start at the beginning, go on to then end, and
then stop. Once we've identified salient passages, if we're doing a literary
reading, we might well read non-linearly, jumping about in Barthesian circles
within the text, or even interlacing our readings of more than one text -
but our experience of a text, in as much as it unfolds syntagmatically, proceeds
one word at a time. Building on this topological metaphor, an 'overview'
of the text becomes possible as a retroactive representation of our reading
experience to ourselves. We might look at the spine of a book on our shelves
if we want to experience the whole text 'at once'. But this is not the same
thing as reading, which always involves seeing the individual trees, and then
reconstructing a wood from our experience of them - we can't take a step back
from our linear reading and survey the wood, except imaginatively.
The use of computers to analyse texts allows us to experience the information
texts contain in different ways. Computers 'read' texts initially in a way
as linear as human reading, it is true, but the information they gather is
organised differently, and can be displayed differently in ways that complement
human reading.
Computer visualisation, for example, can allow access to 'whole' texts,
just as they can allow us to visualize solutions to mathematical problems. Figure
1 is a computer visualisation of the best known solution to the question:
what shape can enclose two equal volumes with the least surface area? As you
can see, the solution to this problem is a 'double-bubble', where two partial
spheres are stuck together. This solution could be represented mathematically
with a formula, but the solution has an intuitive appeal when it is rendered
in a simulated three-dimensional image.
Figure 1 Double bubble
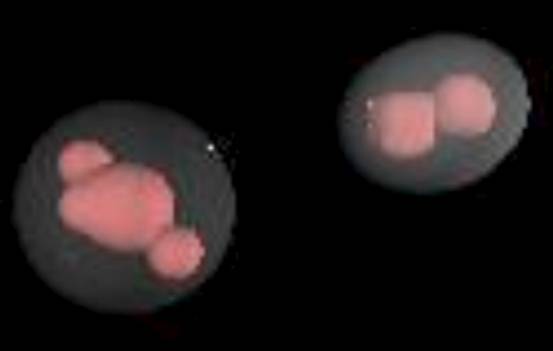
Figure 2 is another three-dimensional image of something
that might not necessarily be understood topographically; here, the information
being represented is a set of frequency counts for select 'content-words'
among three texts. The blob on the left of the picture 'is' Shakespeare's
Richard II and Richard III; the blob on the right 'is' an essay
on the visual representation of Shakespeare's texts. Note how the (admittedly
crude) translation of text into shape allows us to perceive a similarity between
Richard II and Richard III, and their collective dissimilarity
to a contemporary essay on the visual representation of Shakespeare's texts.
The spatial arrangement of the blobs allows us to see this fact about the
whole texts much faster than if we were presented with a page of quotations.
Such technologies have been developed because they enable other 'readers'
-- say individuals searching the internet for certain texts -- to identify salient
items quickly without having to read through everything available in a particular
domain. [1]
Figure 2 Pink blobs
If computers allow us to experience something like a simultaneous (as opposed
to linear), 'total' reading of a text via topographical visualisation, they
also allow us to pay closer attention to the thousand birches surrounding
the three oaks. Strangers to saliency, computers treat all pieces of information
equally: they are just as aware of the 609 usages of the word 'the' in Macbeth
as the 35 uses of 'hand'. To humans trained in the western literary tradition
of reading for 'understanding,' this may seem a pretty useless ability - even
perhaps a blindness - and early concordances and concordancing programs frequently
omit words such as 'the' as being 'too frequent' to be of interest.[2]
In fact, however, differing frequencies of such words may carry important
information about authorship, or other textual features - and differing frequencies
can easily be represented visually by plotting them in imaginary three-dimensional
or two-dimensional spaces.
This paper reports on a pilot project investigating the computer 'reading'
of Shakespeare's texts using Docuscope, a text analysis program being developed
at Carnegie Mellon University.[3] The
paper gives an indication of some of the ways in which computer reading can
surprise us, and perhaps prompt us to ask different questions about Shakespeare's
texts.
What the Machine Does
The easiest way to introduce Docuscope is to begin with one of its output
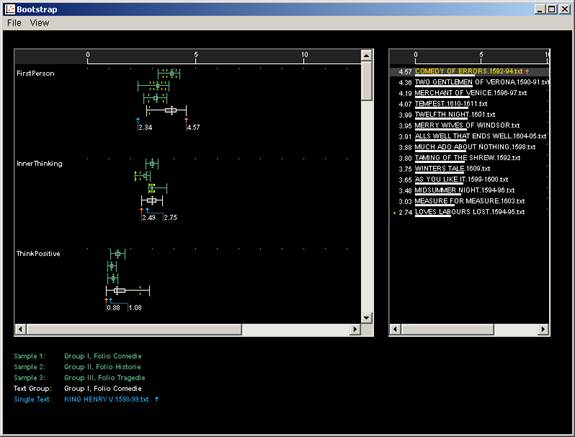
screens. Figure 3 shows a set of results from the first folio Comedies.
The texts analysed are listed on the right hand side of the screen. On the
left hand side of the screen is a list of rhetorical features (FirstPerson,
InnerThinking, ThinkPositive and so on). These features have been identified
by the developers of Docuscope as crucial in setting the genre or discourse
type of texts. When Docuscope 'reads' a text, it uses a set of dictionaries
to identify linguistic items (words and strings of words) which have been
assigned to one of these rhetorical features. Docuscope counts the frequency
of all such items in the texts it analyses, and gives a visual display of
this information. It should be recognized here that the categories Docuscope
uses are themselves the result of "interpretation" or "understanding": a computer
could not itself sort out the salient terms to search for in order to classify
texts along significant rhetorical axes.
Fig 3 Docuscope: folio, first person
In the example screen, the feature 'FirstPerson' has been highlighted (we
will see exactly which linguistic items are counted under this heading in
a moment). The plays in the right hand column are arranged in descending
order of relative frequency of this feature - so we can see that Comedy
of Errors has the highest relative frequency of first person, while Love's
Labour's Lost has the lowest. The values of these relative frequencies
are expressed numerically alongside the title of each play (4.63 for Comedy
of Errors, 2.84 for Love's Labour's Lost) and graphically in a
horizontal bar under each play title.
Moving to the left had side of the screen, we can see that there is a box
plot next to the highlighted term 'FirstPerson'. This box plot gives a visual
representation for all of the results in this analysis and an indication of
the distribution of results in the sample. The two extreme ends of the box
plot mark the upper and lower results (Comedy of Errors at 4.63 on
the right, Love's Labour's Lost at 2.84 to the left). The two extra
dots at the left hand of the plot indicates a threshold at which parts of
the sample have ceased to be relevant for certain kinds of statistical generalization.
The central rectangle in the box plot covers the second and third quartiles
of the results - effectively the middle 50% of results. And the line in this
rectangle represents the median of the sample (the mid-point of all the results).
Thus, the longer the rectangle, the wider the range of results. Below the
highlighted feature of FirstPerson are the other box plots showing the results
for each of the other features listed on the left of the screen.
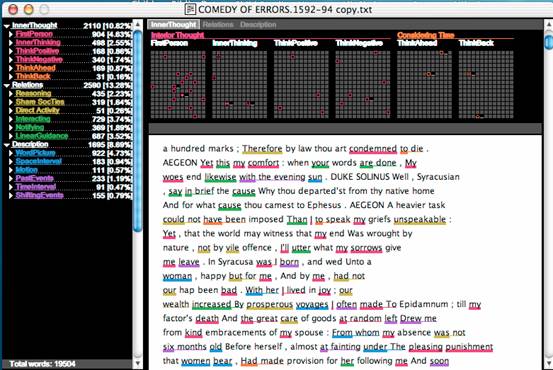
Figure 4 shows a slightly different output screen from Docuscope. Here
we are looking at the results for just one play, Comedy of Errors, but the
rhetorical features are still displayed on the left hand side. Note that
each feature has an overall name (InnerThought, Relations, Description) and
within this is broken down into six subfeatures (for InnerThought, these include
FirstPerson, InnerThinking, ThinkPositive, and so on). On the right hand
side of the screen we can see one of the most useful features of Docuscope:
it allows the user to see instantly what the program is counting in the analysed
text. In the text window, we can see a section of Comedy of Errors,
with the items Docuscope has counted underlined in a colour corresponding
to the rhetorical feature they have been assigned to by the development team.
The text is beginning to take on the characteristics of a surface; our eyes
are attracted to its spatial features rather than its semantic content.
Fig 4 Docuscope: Comedy of Errors1
The grids at the top of the screen give an even more explicitly topographical
representation of the occurrences of each item counting towards each feature
(note where the small squares are highlighted). Here the text begins to resemble
a piano roll, patterned with different occurrences or "holes" that can be
compared for density, distribution and frequency.
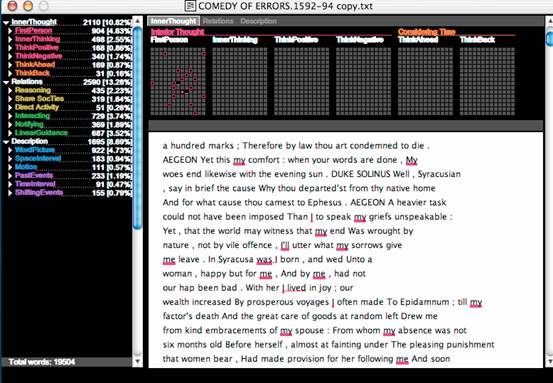
Figure 5 is the same screen as Figure 4, but with all linguistic features
except FirstPerson turned off. This allows us to see what Docuscope is counting
in order to arrive at its frequency totals for this feature: first person
pronouns.
Fig 5 Docuscope: Comedy of Errors2
Docuscope is thus a set of dictionaries which are designed to identify linguistic
items (not just words, but strings of words) associated with a set of predetermined
rhetorical categories ('InnerThought', 'Relations', 'Description' and so on).
The categories themselves reflect the phenomenological approach of its developers,
who view texts as devices for creating distinctive reader-experiences -- that
is, for orienting readers with respect to objects, actions and scene in particular,
patterned ways. The program also contains statistical analysis tools which
allow the comparison of the relative frequencies of these items between different
texts. Its third element is the visual interface which allows the user access
to this comparative data.
Docuscope was created for use on contemporary texts, and its rhetorical
categories were not developed with Early Modern texts in mind. The program
is still in development, but it is being used at Carnegie Mellon University
in undergraduate composition classes to allow all of the students in a class
to compare their work without having to read 20-30 different assignments.
Instead of reading others' work, students upload their pieces to Docuscope
and 'read' the graphical information. This allows them to see immediately
different stylistic decisions taken by students when approaching similar writing
tasks - using higher frequencies of first person forms, for example.
In this pilot study, we have taken an unmodified version of Docuscope and
used it to 'read' Shakespeare's First Folio. Our aim was to investigate the
extent to which Docuscope's categories remain valid for Early Modern texts,
and to see if the program 'saw' anything of interest in the text. In advance
of the test, we wondered if the program would have any sensitivity to date
of composition or authorship, but this was principally a 'suck it and see'
experiment. This is what we saw.
Docuscope 'Reads' the First Folio
For the test run of Docuscope on the first folio plays, we took open source
modernised texts of the first folio plays and fed each play into Docuscope
as a separate text file. Docuscope analysed each play, producing frequency
counts for all of its linguistic features. We then put these frequency counts
through a standard discriminant analysis statistical package. In discriminant
analysis, the program makes a series of statistical comparisons between the
results for a sample, attempting to sort the items in a sample into similar
and dissimilar groups. The program also looks for those features which are
most important in producing difference and similarity. In other words, the
program tries to sort the first folio plays into similar and dissimilar groups,
while also identifying the rhetorical features which play the most significant
role in distinguishing these groups.
The program we used automatically attempts to resolve samples it is given
into two groups. The results of this sorting are given in Figure 6.
Fig 6 Group 1 and Group 2
It will be seen from Group 1 and Group 2 in Figure 6 that Docuscope and
the discriminant analysis program have divided the plays almost exactly according
to the folio genres of History (Group 1) and Comedy (Group 2).[4]
There are some anomalies in this grouping, which we will come to, but we want
to underline here the interest of this result: a program which knows nothing
about the folio divisions or the largely content-based definitions of genres,
has been able to reproduce them solely by counting the relative frequencies
of linguistic items. This, it seems to us, is an unexpected result which
deserves further study.
First, a word about the anomalies. Readers will see that Comedy of Errors,
A Midsummer Night's Dream, and The Tempest are placed in Group
1 by the program, alongside Histories; Henry VIII, on the other hand,
is placed in Group 2, with Comedies. We will investigate these results more
fully in future work, but for now, note that the three aberrant comedies are
grouped together by the program (highly similar texts are placed next to each
other) and that there is a gap between them and the next group of histories
(gaps within the group suggest a degree of difference). As for Henry VIII,
its evident difference on this result from the other histories is perhaps
not surprising given its frequently remarked generic differences, its lateness
of composition, and its collaborative nature.
These anomalies noted, what features of the Comedies and Histories allow
Docuscope to distinguish them? The final three Figures give an indication
of the linguistic differences between the Comedies and the Histories and also
go some way to underlining the 'inbetween' status of the Tragedies. In each
of these figures (7, 8, and 9), Docuscope is combining the individual texts
in each of the folio genres and treating them as a member of a group -- Comedies,
Histories and Tragedies. The overall results for each group are then compared
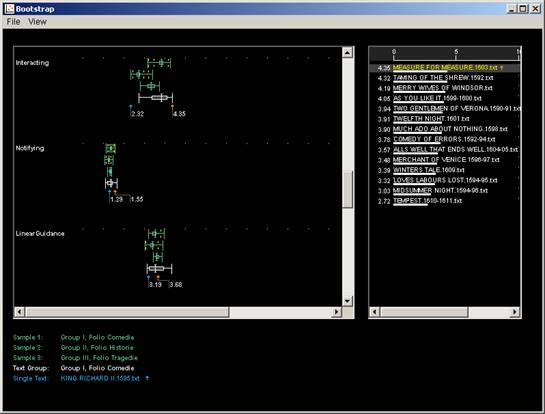
using box plots. Thus, in Figure 7, we have results on the left hand side
of the screen for three rhetorical features: Interacting, Notifying, and Linear
Guidance. There are four box plots against each rhetorical feature: in each
case, the first box plot records the results for all of the Comedies, the
second for the Histories, the third for the Tragedies, while the fourth gives
a composite result for all of the folio plays together.
Fig 7 Docuscope: folio genres, Interacting
Using the inner rectangle, it becomes easy to compare results for each feature,
since if the rectangles of adjacent plots do not overlap, we can say that
the differences between the results are statistically significant. Thus,
for the first feature, Interacting, we can see that the rectangles for Comedies
and Histories are a long way apart - suggesting statistically significant
differences for these texts on this rhetorical feature. The rectangle for
Tragedies, however, lies in between the rectangles for Comedies and Histories,
almost overlapping with both. Interacting, therefore, is a feature which
can be used to differentiate between Comedies and Histories, but is not useful
for differentiating Tragedies from either.
Moving down to Notifying, we can see that this is a much less frequent feature,
and that the samples do not differ significantly from each other (the rectangles
are very close together). Similarly, LinearGuidance does not clearly distinguish
the genres: they all use it at roughly the same frequency.
To return to the result for Interacting for a moment, it is possible to
offer a content based explanation for this difference between Comedies and
Histories. It seems intuitively likely that Comedies, with their fast-paced
dialogue, will feature more interaction than Histories, where we might expect
longer set-piece speeches. Thus the results of the computer 'reading' can
be said to conform to a human expectation of the type of discourse found in
the plays.
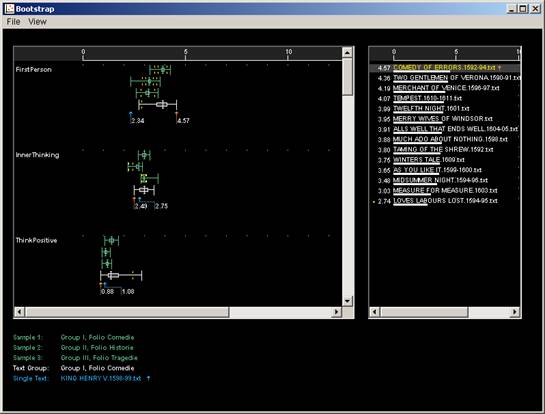
Moving on to Figure 8, we return to the feature FirstPerson. Here, we can
see by comparing the rectangle plots that the Comedies have significantly
more first person forms than either Histories or Tragedies. Perhaps the difference
between Comedies and Histories on this feature is not surprising and could
have been predicted, but it seems to us that the difference between the Comedies
and Tragedies is counter-intuitive: Comedy is supposed to be the genre of
society; Tragedy of the individual. Soliloquy might have been expected to
boost the frequency of first person in the Tragedies. If we see Early Modern
plays as one of the places where the modern 'self' is constructed, perhaps
we have been looking in the wrong place with our concentration on Hamlet:
should we turn instead to Comedy of Errors and The Two Gentlemen
of Verona?
Fig 8 Docuscope: folio genres, FirstPerson
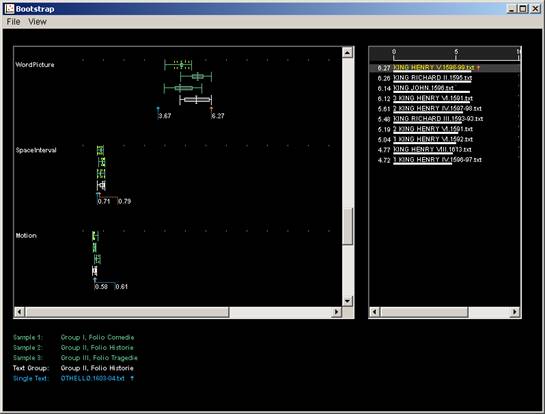
Figure 9 provides us with a feature which distinguishes Histories from Comedies.
This feature is termed WordPicture, and counts items such as concrete and
visual nouns and verbs. Note again the characteristic result of a significant
difference between Histories and Comedies, with the Tragedies lying in between.
Going back to human reading techniques, perhaps we can account for this result
by appealing to the concrete visualisation of the world and geographical space
which are frequent in Histories.
Fig 9 Docuscope: folio genres, WordPicture
Genre, History and Attention
Before we make our grand closing claims, it is necessary to post a series
of caveats. Docuscope is a program under development: the dictionaries are
being refined as tests like the one reported here are made. Docuscope is
designed to work on contemporary prose, not Early Modern blank verse: there
is no guarantee that its rhetorical features are valid for Early Modern English,
or that its dictionaries identify all the relevant items in Early Modern English.
The texts we used for these tests were public source texts containing speech
prefixes and stage directions: for future work we are preparing a set of stripped
texts. The results reported here come from relatively random 'messing about'
with the program to see what would happen: we had no clear research objective
or hypothesis beyond the ideas that Docuscope might be sensitive to date of
composition or authorship.
In the event, we think our results are sufficiently interesting to put aside
for the moment worries about Docuscope's suitability, to justify publication,
and to encourage further work. We think several general areas for further
research are suggested by these initial results:
Genre Theory. Throughout antiquity and the Renaissance, theories
of genre have focused on a work's content, mode of presentation, and social
function. Thus Ben Jonson, building on classical and Italian models, could
argue for the salutary value of comedy--a genre which he saw as typically depicting
the vices of the lower and middling social classes--by countering claims that
audiences simply repeat the nasty behaviours they see on stage. Rather, he
argued, the spectator of comedy learns to avoid the behaviours he or she observes.
In order to make these claims, Jonson had to have a sense of what the genre
'comedy' was about and what it was for. Similarly, contemporary genre theorists
think about the relationship between particular genres like the Epic and particular
historical settings or ideological programs (for example, colonial expansion).
As a critical tool, then, genre is itself the product of innumerable reading
encounters and discussions of texts: it is an artefact of literary history,
like the texts themselves.
Docuscope's encounter with early modern texts--limited to counting things
and comparing numerical results--has in effect produced another one of these
literary-critical artefacts, albeit a statistical one. The mere existence
of such a statistical recipe for 'genre' suggests that there is an empirical,
linguistic basis to interpretive classes such as Comedy and History, classes
which have traditionally been defined in qualitative terms. (Indeed, the
very word genre reveals this qualitative thrust, since it literally means
"kind.") At the broadest level then, Docuscope is a machine that makes us
think about the nature of literary classifications and the way they are experienced
and constructed. New questions emerge that might not have been asked using
previous methods. What is the linguistic texture of Comedy and History and
how is this texture, to the extent that it is distinctive, related to the
various phenomenological, social and historical factors that constrain literary
production and reception? What, moreover, might the effect on our theories
of genre be if it turns out that Tragedy is not as linguistically distinct
as other genres? This kind of linguistic-physiognomical approach to texts
generates new questions that must be answered by further reading and historical
contextualization. We are not the first to ask such questions, but we have
a tool that will let us formulate and test them with more empirical clarity
and speed. [5]
Prosthetic Reading. Tools like Docuscope allow human readers to
pay attention to very high frequency items we usually ignore as part of the
background noise of reading. As we have seen in the case of first person,
these items can be linked to ongoing arguments in literary history, such as
the hotly debated claim that modern self-hood emerged first in Early Modern
Tragedy. Being able to pay attention to massively iterated linguistic items
with the aid of such a 'prosthetic' may thus provide new evidence for existing
debates, or provoke different questions. The tool raises questions about
reading as well. If certain linguistic features correlate with the rise of
certain cultural or literary forms, perhaps we have to rethink the relationship
between what goes 'unnoticed' in a text and the real experiences and social
attitudes that the text may nevertheless shape or express. If there is a
correlation between literary styles (dramatic genres), cultural forms (like
possessive individuality), and linguistic features (first person reference),
how are these factors to be understood in relation to one another given these
results? How, moreover, do we explain the effects of massively iterated textual
features on individuals who may not consciously attend to their persistent
recurrence? Is there a 'cultural,' 'ideological' or 'unconscious' connection
between these linguistic patterns and what Raymond Williams has called the
'structure of feeling' in a particular place and time? We believe that this
kind of research may, at some point in the future, make it possible to demonstrate
the effects of recurring linguistic features on readers and communities in
much the same way as others have done using categories like culture, ideology
or the unconscious. If this approach bears fruit, perhaps we should be prepared
to think of texts as contraptions for the direction of attention instead of
transmitters of information, concepts, or worldviews. As the old maxim of
the trees suggests, some things are just too obvious to be noticed; they may,
nevertheless, exert a shaping power on what readers experience outside the
locus of conscious attention.
Thus if the modern linguistic features that have been identified in this
study are even partially useful for tracking cultural and linguistic shifts
that would otherwise go unnoticed, a significant area of research remains
to be undertaken. Central to that project is the creation of a corpus of
texts which can be analyzed 'prosthetically' and--much more daunting--the incremental
sophistication of the linguistic categories being used. Part of this refinement
involves un-modernising the things a program like Docuscope counts. A version
of this program containing early modern words and phrases would thus be invaluable.
But historical difference is not the only factor that might need to be accounted
for in further explorations. We may also have to re-think what it is that
we are counting when we approach texts as surfaces or strings rather than
windows into another world or soul.
Counting Things. Clearly Docuscope is not totally blind in what
it counts, since its categories (FirstPerson, etc.) embody a particular view
(a poetics, a rhetoric) of how texts communicate and what makes them distinct.
The empirical basis of 'genre,' then, is empirical only to the extent that
certain interpretations of what it is important to 'look for' have been tested
against others in a range of texts deemed 'relevant'. Genre is not popping
out of texts ex nihilo. But it is--and here is the theoretical significance
of our claim--showing itself to be 'legible' at levels that are not immediately
accessible to the conscious reader. A critical project that uses tools like
Docuscope to investigate historically specific notions of genre thus adds
to the body of material evidence we use as we try to understand texts and
the readers/writers who encounter them. The interpretive status of claims
like 'selfhood in the western tradition emerges with certain early modern
genres of drama' remains the same. The evidence for such claims, however,
may lie as much on the surface of very large textual objects as it does in
the breasts of fictional characters who have "that within which passeth show'.
Notes
[1] As one of our anonymous referees
pointed out, such computer approaches to the content analysis of texts date
back to the sixties (see Philip J. Stone, 'The General Inquirer: A computer
system for content analysis and retrieval based on the sentence as a unit of
information', Behavioral Science 7 (1962), pp. 484-94; and 'Improved
Quality of Content Analysis Categories: Computerized Disambiguation Rules for
High-Frequency English Words' in G. Gerbner et al. (eds.) The Analysis of
Communication Content (1969, New York) pp. 199-221).
[2] For example, the Arden Shakespeare
CD-ROM (1997) has a 'stop list' of words, explained as follows: 'A stop list
is a list of words that are not tracked by the search function, due to their
excessive frequency. The stop list includes very common words that are seldom
useful to search for.' (General Help > Searching > Advanced Searching
> Narrowing your search > The Stop List).
[3] Docuscope was designed at Carnegie
Mellon University by David Kaufer and Suguru Ishizaki. A study of Docuscope's
categories can be found in David Kaufer et al, The Power of Words: Unveiling
the Speaker and Writer's Hidden Craft. Lawrence Erlbaum & Associates,
2004. The statistical reliability of these categories in distinguishing genres
of modern English has been analysed by Jeff Collins, Variations in Written
English Characterizing Authors' Rhetorical Language Choices Across Corpora of
Published Texts, Doctoral Dissertation, Department of English, Carnegie
Mellon University, 2003.
[4] We have removed the Tragedies from
this result as the program does not identify them as a distinct group. Some
reasons for this are given later in this paper, and we will be investigating
this further in future work.
[5] Barron Brainerd ('Pronouns and genre
in Shakespeare's drama', Computers and the Humanities, 13 (1979), pp.
3-16) has also sought to correlate linguistic feature with genre, and the sensitivity
of second person singular pronouns to genre is confirmed by Jonathan Hope (The
Authorship of Shakespeare's Plays, Cambridge University Press, 1994, chapter
4, with some caveats about Brainerd's method on pages 63-4).
Works Cited
Brainerd, Barron. 'Pronouns and genre in Shakespeare's drama'. Computers
and the Humanities, 13 (1979), 3-16.
Collins, Jeff. Variations in Written English Characterizing Authors'
Rhetorical Language Choices Across Corpora of Published Texts, Doctoral
Dissertation, Department of English, Carnegie Mellon University, 2003.
Hope, Jonathan. The Authorship of Shakespeare's Plays. Cambridge
University Press, 1994.
Kaufer, David, et al. The Power of Words: Unveiling the Speaker and Writer's
Hidden Craft. Lawrence Erlbaum & Associates, 2004.
Stone, Philip J. 'The General Inquirer: A computer system for content analysis
and retrieval based on the sentence as a unit of information'. Behavioral
Science 7 (1962), 484-94.
Stone, Philip J. 'Improved Quality of Content Analysis Categories: Computerized
Disambiguation Rules for High-Frequency English Words' in G. Gerbner et al.
(eds.) The Analysis of Communication Content (New York, 1969), pp.
199-221.
Responses to this piece intended for
the Readers' Forum may be sent to the Editor at M.Steggle@shu.ac.uk.