
Library Workflows to Provide Emblem-Level Descriptions and Access
Timothy W. Cole
Myung-Ja Han
University of Illinois at Urbana-Champaign
t-cole3@illinois.edu
mhan3@illinois.edu
Timothy W. Cole and Myung-Ja Han. “Library Workflows to Provide Emblem-Level Descriptions and Access." Emblem Digitization: Conducting Digital Research with Renaissance Texts and Images, ed. Mara R. Wade. Early Modern Literary Studies Special Issue 20 (2012): 8. <URL: http://purl.oclc.org/emls/si-20/WADE_Cole-Han-EMLS.htm>.
Abstract
1. In organizing, making accessible, and presenting retrospectively digitized collections to their end users, academic libraries must anticipate how the digital version of the collection will be used by scholars and must develop processing workflows appropriate to the unique attributes of the collection and its primary user group. Such workflows must address the granularity of the digitized content and the question of how best to exploit options for presentation and citation made possible by digitization. This will maximize the usefulness of the digital collection and allow it to best serve scholars’ research needs. In September of 2009, the University of Illinois at Urbana-Champaign and the Herzog August Bibliothek (HAB), Wolfenbüttel received funding from the National Endowment for the Humanities (U.S.) and the Deutsche Forschungsgemeinschaft (Germany) for the Emblematica Online project.[1] As part of this project, the University of Illinois has digitized 373 emblem volumes from its Rare Book and Manuscript Library collections, including a distinguished subset of fifty-four German language emblem volumes. This paper discusses the workflows that have been developed and implemented at Illinois to process digital files created during this digitization effort. These workflows involve the creation of metadata at two levels of granularity, the creation and linking of identifiers for digitized content at both levels of granularity, and the creation of new derivative views of emblems and emblem components to facilitate access to and scholarly reference of emblem resources. We discuss how we are leveraging the emerging SPINE metadata standard[2] for describing emblems and emblem books, how we use Extensible Markup Language (XML) and ancillary technologies such as transforming XML stylesheets in our workflows, and how we have implemented and are exploiting ImageMagick image-processing software[3] and a local instance of the aDORe Djatoka Web-friendly image service application[4] to isolate views of emblems and emblem pictura to facilitate presentation and use of digitized emblem content, all with the ultimate goal of facilitating emblem scholarship.
Introduction
2. As academic libraries continue retrospective digitization work, we are learning how best to select, organize, maintain and present digitized content to our end users. Frequently encountered are issues to do with granularity of digital content and with how best to exploit the additional functionality possible with digital content. New kinds of content and new scholarly needs and expectations regarding this content require libraries to carefully evaluate how to translate traditional workflows and models of curated content into the digital library domain. The workflows we've built around the digitization of emblem books illustrate how libraries can handle these issues in a manner that serves the objectives of our users.
3. Many of the Emblem books in our Rare Book and Manuscript Library at Illinois were already well described as books in our online catalog system before we began the current project, but each emblem book contains finer grained elements that are individually important to emblem scholarship and pedagogy as well. When digitizing an Emblem book, the library should make these finer grained elements individually addressable and discoverable, while simultaneously maintaining access to the whole book as a discrete entity and as context for the more fine grained elements.
4. This required us to implement new methodologies and adjust our traditional cataloging workflows to support describing individual emblems. It also required that we exploit digital technologies to go beyond simply reproducing single print page images, e.g., to go beyond recreating an exact digital analog of the printed book, towards a model that allows users to retrieve digital surrogates for a multi-page emblem or, at the other extreme, to retrieve only a partial page view of an individual emblem sub-component, such as the pictura as individual entities. This in turn required that we find new ways to persistently identify digital surrogates for the emblem book and emblem book components at multiple levels of granularity, while at the same time still insuring and making clear the provenance of the digital views of these information resources.
5. The current project, building on pilot work described elsewhere (Billings) will increase our collection of fully described (i.e., at both book and emblem level) German emblem books at Illinois from twenty to fifty-four volumes encompassing a new total of 8,729 emblems. The following discussion of the library workflows created to support the Emblematica Online project addresses in order: enrichment and normalization of book-level descriptions; the ways in which we are leveraging our large-scale digitization collaboration with the Open Content Alliance (OCA) to perform scanning of Emblem books; our use of the emerging SPINE metadata standard for emblem and emblem book description; the technical infrastructure created to merge book and emblem-specific metadata, provide persistent identification of emblems, and support views of digitized content that goes beyond simple digital surrogates of individual print pages. We also briefly describe plans for a new collaborative portal to provide access to digitized emblem content at the University of Illinois, at the Herzog August Bibliothek Wolfenbüttel, and elsewhere. The work described here is illustrative of the kind of approach libraries must take in translating traditional workflows and models of curated content to the digital realm in order to deal with new forms of content while simultaneously addressing user needs and expectations in regard to this content.
Enriching Book Level Descriptions
6. Emblems and components of emblems appear in context. Our current work focuses on digitizing and providing access to digital copies of complete emblems as they appeared within printed books published during the European Renaissance, but emblems and emblem pictura also appear associated with artifacts such as porcelain (Chilton), as elements of building architectural features (Böker and Daly), and in a range of other contexts. Complete, high-quality descriptions of emblem containers are therefore essential to facilitate the discovery and scholarly study of emblems in context.
7. At the start of our project, the available library catalog records for the Emblem books to be digitized were of varying levels of completeness and quality. Before sending books to the scanning center for digitization, bibliographic records for each Emblem book were examined and enhanced according to the rules outlined in Descriptive Cataloging of Rare Materials (Books). As necessary, the Rare Book and Manuscript Library staff at Illinois faithfully transcribed title, edition, and publication-related information, such as date, publisher, and publication or print information. Copy and edition-specific information, including references to specific standard bibliographies and emblem book indices, was added. Identifiers added to book catalog records were drawn from McGeary’s & Nash’s Emblem books at the University of Illinois (1993), the Verzeichnis der im deutschen Sprachraum erschienenen Drucke des 17 Jahrhunderts[5], John Landwehr’s French, Italian, Spanish, and Portuguese Books of Devices and Emblems 1534-1827: A Bibliography (1976), and other similar sources. In addition, physical and intellectual descriptive information, such as bound with statement, book plates found, binding details, insertions (prospectuses, clippings, etc.), and provenance information regarding books digitized, was added as appropriate.
8. Records in the University of Illinois Library’s online public access catalog were then updated to reflect the enhancements made in Emblem book descriptions. As described below, automated processes were then run to merge these enhanced bibliographic records with descriptions and motto transcriptions for each individual emblem included in our sub-collection of digitized German-language Emblem books. Resultant merged descriptions of book and contained emblems were then made available as SPINE-compliant metadata records conformant to the XML schema developed at the Herzog August Bibliothek, Wolfenbüttel, Germany (Stäcker).
Leveraging the Library's Participation in the Open Content Alliance
9. In 2006 the University of Illinois at Urbana-Champaign joined the OCA. This program, under the auspices of the Internet Archive,[6] provides a scalable, cost-effective way for members to digitize important and unique book collections. When Illinois joined the OCA, a satellite OCA scanning center was established at the Library’s offsite remote storage facility. (Through the end of September 2011 more than 27,411 volumes from University of Illinois Library collections have been digitized.) The Library has developed a baseline workflow for the OCA project, not only to deal with the process of selecting and sending books to OCA scanning center, but also to retrieve selected digital derivatives for local storage and reuse in projects from OCA after scanning is complete. To meet the specific needs of the Emblematica Online project a variant of our baseline OCA workflow was developed.
10. The approach of leveraging our OCA involvement for Emblematica Online allowed us to obtain the economy of the large-scale OCA Initiative for our much smaller project. Cost per page scanned by OCA is approximately ten cents U.S. The standard OCA has set for scanning quality is relatively high and is more than adequate to meet the day-to-day needs of our audience of emblem scholars. (In a few instances, nothing can replace in-person examination of an emblem; but with good quality digital surrogates, much useful pedagogy and research can be done remotely.)
11. As is to be expected in such a large undertaking, scanning errors do occur, e.g., a missed page, an out-of-order page image; however, the OCA staff have worked closely with project staff to minimize this problem, and have been willing to reorder or rescan and add in any page images missed during initial scans. (Of course, the labor required to find a page, that has not been scanned, is not insignificant and must be borne separately by projects such as ours.)
12. There are limitations that come with the decision to rely on OCA to scan our emblem collections. OCA scanning equipment, while quite flexible, cannot work with margins that are too small or with volumes having dimensions exceeding certain limits. Additionally, some volumes in our emblem book collection are simply too fragile to transport offsite and/or to scan using the OCA equipment, which for example, requires glass to be lowered onto each page as it is scanned. Of approximately 730 volumes in the emblem collections in our Rare Book and Manuscript Library at Illinois, 373 (about 51%) have been scanned by OCA. The volumes not scanned exceed dimensional limits, have insufficient margins, or were deemed too fragile to scan at this time through OCA. We will leave these volumes to be scanned in house at a later point in time (and at a significantly higher cost per page).
13. Raw page images created by OCA scanning are archived from camera-format originals to the JPEG 2000 format. Through an automated process, OCA also creates a second set of same resolution, cropped and de-skewed JPEG 2000 image files. We find the JPEG 2000 format a useful and robust format well matched to the needs of the Emblematica Online project and compatible with software used to manipulate and present scanned data to end-users. Resolution (relative to original print) of these JPEG 2000 images varies between 300 and 500 dpi (dots per inch). OCA observes file naming conventions which make it easy to algorithmically recognize page order. For the purposes of our workflow for the Emblematica Online project we retrieve and make use of both the raw and cropped & de-skewed JPEG 2000 image files.
Creating SPINE Records for German Language emblem books
14. For each of the German language emblem books digitized, a SPINE metadata record in XML format is created, describing the emblem book and each emblem within the book. The SPINE standard is based on a paper published by Stephen Rawles titled A SPINE of Information Headings for Emblem-Related Electronic Resources (2004). The major elements proposed by Rawles have been incorporated into a XML schema developed by Thomas Stäcker at HAB. Stäcker’s schema also borrowed from the Text Encoding Initiative (TEI), in particular borrowing the teiHeader element which provides detailed semantics for book bibliographic description. The SPINE schema has been updated to version 1.2 that also supports the Metadata Object Description Schema (MODS) as its book level description.
15. The SPINE root element for description of an individual emblem volume contains three child components: teiHeader (or MODS), copyDesc, and emblem. The teiHeader (or MODS) includes elements that work well for describing the bibliographic attributes of a specific edition or printing of an emblem book, i.e., the Emblem book considered as a Manifestation in Functional Requirements for Bibliographic Records (FRBR) Group 1 entities (IFLA Study Group). The copyDesc element (which can be repeated) is intended to describe “the copies on which the new digital works are based,” (Rawles 21). Thus the copyDesc element is used to record information, including ownership, regarding the physical copy or copies digitized as representative of the Emblem book printing or edition. The copyDesc element contains a sub-element, digDesc, describing digitization details for digital instances created from the specific physical copy. Finally the emblem element (also repeatable) holds emblem-specific information, including information about emblem sub-components such as motto, pictura, subscriptio, etc. Room is provided in the schema at this level to record controlled vocabulary descriptors, e.g., Iconclass[7] headings, describing each emblem and/or its child components.
Transforming & merging metadata
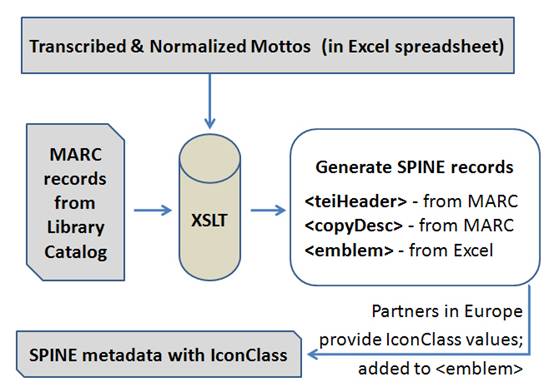
Figure 1: Depiction of workflow used to create SPINE metadata records.
16. As depicted in Figure 1, the process of creating a SPINE metadata record for one of our emblem volumes involves transforming and merging the online library catalog record for the book with a Microsoft Excel spreadsheet which contains transcribed and normalized mottos for each emblem contained in the volume. This transformation and merger is accomplished using transforming XML style sheets (XSLT). This part of the workflow proceeds as follows.
17. Once an emblem volume from our collection has been scanned by the OCA and the image files downloaded and saved to the Emblematica Online project Web server at the University of Illinois, an Excel spreadsheet for the volume is created. This spreadsheet is initialized with two links, the first pointing to the MAchine Readable Cataloging (MARC) XML format bibliographic record in the Illinois online library catalog, and the second pointing to the local digital copy of the volume at Illinois. Project collaborators both within and external to the library are then called upon to transcribe and normalize the mottos for each emblem in the volume. (This illustrates the facility and increasing frequency with which libraries now collaborate with domain experts in describing digitized content.) The language for each transcribed/normalized motto is captured. If page numbering and/or emblem numbering was present in the printed copy of the emblem volume, this information also is captured. Motto transcriptions and normalizations, including language and numbering information is saved into the spreadsheet for the volume which is then vetted by other project staff and finally by Professor Mara Wade, the Illinois project's Principle Investigator. The Excel spreadsheet is then saved as XML (i.e., is saved in Microsoft's Excel 2003 XML spreadsheet format) to facilitate transformation and merger of the MARC record.

Figure 2: Comparison of MARC XML (on left) to teiHeader XML (on right)
18. A sequential list of permanent emblem identifiers (based on the CNRI Handle System[8]) is assigned and registered for the volume (see further discussion below). The number of emblem identifiers required is calculated from the row count of the volume’s spreadsheet. The XSLT then takes over and begins by fetching the MARC XML record for the book from a Web service maintained by the Library. The XSLT invokes a template to transform the MARC XML record for the book into a teiHeader XML node. For this purpose we repurposed an existing MARC to teiHeader transformation stylesheet created during a previous project. The main bibliographic elements of the MARC record are mapped to the sourceDesc section of the teiHeader, including book title, author(s), publisher, physical description, and so on. Some boilerplate values which are consistent for all the volumes in the project are used to populate select other elements in the teiHeader. References to specific standard bibliographies, recorded in MARC note fields, are transformed to the teiHeader note element in sourceDesc in a detailed way. The title of the standard bibliography is added to the teiHeader bibl element under note and the identification number of the book in the bibliography is included in an idno attribute. Figure 2 compares a portion of the original MARC XML for a book to corresponding portion of the derived teiHeader XML side-by-side.
19. While most of the original print book bibliographic information is transformed into teiHeader/sourceDesc, much of the digital representation-specific information that appears elsewhere in the teiHeader XML -- e.g., values that appear in teiHeader/fileDesc/publicationStmt -- is boilerplate, consisting of fixed values that are the same for all emblem books in the collection. The same is true for much of the copyDesc element which follows the teiHeader element in the SPINE metadata record. The copyDesc element documents the owner of the print copy digitized, i.e., the University of Illinois Library at Urbana-Champaign for all of the emblem books we are digitizing at Illinois.
Mottos, Links, and Iconclass Headings
20. The last part of the SPINE metadata record describes each of the individual emblems contained in the volume. These nodes are initially created and partially populated using an emblem-specific template in the XSLT. This template is called once for each row of the spreadsheet. Motto transcriptions, normalizations, and language are recorded, along with any page or emblem-level numbering from the original print volume.
21. At this point in the process we have a valid SPINE metadata record describing the emblem volume and all emblems within it. However, the records created to this point in the workflow are not complete enough to meet end-user needs. Though identifiers for each emblem have been registered and added to the SPINE metadata, and links included in the metadata pointing to available instances of the digitized volume as a whole, we have not yet added links to views of each emblem and each emblem's pictura. Accordingly we have a workflow (detailed below) to create and mint links to emblem-level and pictura-level views.
22. As a final step, Iconclass headings are added for each emblem pictura. (Iconclass is a hierarchical vocabulary for works of art.) Because Iconclass headings have been translated into five languages (with more in prospect), resource descriptions that include Iconclass headings are immediately more discoverable in multiple languages. Iconclass is designed to provide descriptors that identify the significance of entire scenes, as well as, or, individual elements represented within an image. Iconclass is the only controlled vocabulary explicitly identified in the SPINE format (Rawles, 28) and has been embraced by the emblem community because it provides “a standardized controlled vocabulary […] suitable for the description of emblematic images…” (Graham 16).
23. Proper
application of Iconclass in describing emblem pictura requires extensive
knowledge of art history and related domains. Accordingly, for Emblematica
Online we are outsourcing Iconclass heading assignments to colleagues at
Arkyves[9] and Foto Marburg.[10] Illinois will provide
Arkyves our SPINE metadata records, including links to emblem and pictura-level
views, and they will recommend Iconclass headings for each emblem pictura.
Figure 3 shows a typical SPINE metadata record emblem node once Iconclass vocabulary codes and emblem and
pictura view links have been added.
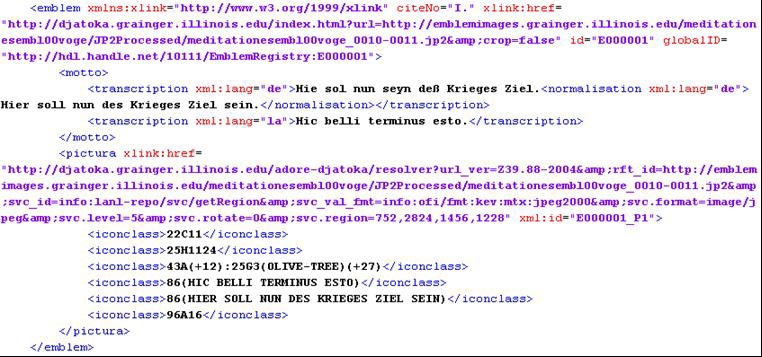
Figure 3: A typical emblem node from a SPINE metadata record
Identifiers & the Emblem Registry at the University of Illinois
24. As discussed above, SPINE metadata records describe entities at multiple levels of granularity, both physically and intellectually. To be directly addressable each entity must be explicitly identified. In addition to supporting addressability for access, identifiers allow relationships between entities to be expressed. While libraries are quite familiar with issues of bibliographic identity, library practice is less settled with regard to the coining and use of Web-friendly identifiers for digital resources and representations.
25. In recent years a useful model of the Web as comprised of linked data entities -- i.e., akin to large, highly distributed linked database -- has emerged (“Linked Data”; “LINKINGOPENDATA”). This view favors globally unique, persistent, HTTP protocol, dereferenceable Uniform Resource Identifiers (URIs) for all resources. The act of translating the URI of a resource into a Web server request for metadata about or a representation of the resource is termed dereferencing the URI. Consistent with the work of the larger Semantic Web community (“W3C Semantic Web”), the linked data model of the Web also differentiates between information resources, representations of information resource, and URIs for concepts and real-world objects (“Cool URIs for the Semantic Web”), commonly known (for historical reasons) as non-information resources. There are striking parallels between some aspects of this view of object identification on the Web and the definitions of group 1 FRBR entities.
26. In the Linked Data model, information resources must have one or more representations that can be accessed via the Web by dereferencing the URI of the information resource. Posted to a Web server and given a URL (subclass of URI), a specific digital instance of an emblem pictura would be a good example of an information resource; assuming it could be disseminated in JPEG format, the representation of this resource would then be the JPEG file fetched by your Web browser when it dereferences the URL.
27. Non-information resources are all other resources having HTTP URIs, including those that are entirely outside the information space of the Web. (The term itself is poorly coined and is now deprecated, but usage persists.) From the Web perspective, an individual person is an example of a non-information resource. In other words, it can be useful to identify an individual for the purpose of stating that he or she was an agent involved in the creation of a Web document, but absent a Star Trek transporter, a person cannot be retrieved from the Web; so, a HTTP URI assigned to a person identifies a non-information resource. When dereferenced instead of obtaining a file (a representation) of the person, you receive information describing the person, i.e., metadata. An emblem considered as a manifestation of art or literature is also a non-information resource; as a manifestation, the emblem is conceptual and so cannot be retrieved via the Web.[11] Instead if you dereference a URI assigned to an emblem as a manifestation, you should receive metadata describing the emblem, and in most cases, links to information resource URLs that yield digital photographs of the emblem in JPEG or other image formats.
28. In our application this leads naturally to a bimodal approach to identification of digitized emblematica on the Web. Attributes are provided on SPINE metadata record elements (globalBookID and globalID) which take as values the URIs assigned to emblems and emblem volumes considered as manifestations of literature, i.e., as abstract, scholarly, non-information Web resources. Separate XLink[12] href attributes are allowed on SPINE metadata elements to express links to specific digital instances of these emblems and emblem books, i.e., to selected information resources which can serve as convenient online surrogates for viewing emblems and emblem books. The latter XLink href links represent a level of identification by exemplar. Though useful for presentation, XLink href links are not appropriate for scholarly reference unless what is being said is only to do with a particular digital instance of an emblem or emblem book, rather than about the emblem or emblem book printing in a more general scholarly context. We can anticipate that the format and location of specific digital surrogates is likely to change over time; conversely, identifiers assigned to emblems and emblem books considered as abstract manifestations of a work of art or literature should persist.
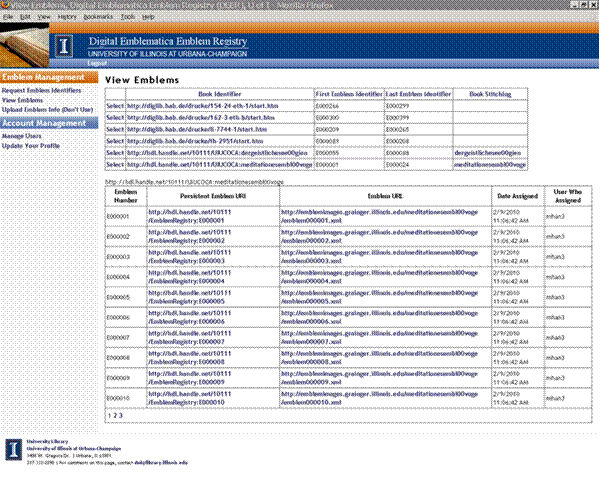
Figure 4: Summary display of information maintained in the Illinois Emblem Registry
29. The requirement of such a bimodal approach is that URIs used in Emblematica Online project for emblems should be thought of as URIs for the abstract manifestations of an emblem as a work of art or literature. These URIs then should be maintained and should reliably dereference to a description of the work (i.e., a non-information resource) with links to digital surrogates or representations. To accomplish this for individual emblem resources, Illinois has created an Emblem Registry and is exploiting the CNRI Handle architecture (the same architecture underlying Digital Object Identifiers, DOIs) to mint non-information resource URIs for emblems. See figure 4 for a summary display of the information maintained in the Illinois Registry for each emblem. Notice that each emblem is associated with both a persistent URI -- used to identify the emblem as an abstract manifestation of an artistic and literary work -- and with a separate URL -- potentially less persistent and pointing to a description of the emblem with views of the emblem linked or embedded. The latter is what you get back when you dereference the emblem's persistent URI (i.e., the emblem's handle). The metadata description of the emblem with links to digital surrogates can be migrated and can change and expand over time, for instance can add links to additional digital surrogates and digitization derivatives, even as the emblem's persistent URI (handle) remains unchanging.
Generating Emblem and Pictura Views
30. Emblems are irregular in form; they come in different shapes and sizes. Emblems include both graphic and textual elements, e.g., a motto (text), a pictura (graphic), a subscriptio (text), and a commentatio (text). Together these elements may span multiple pages or parts of pages, or they may all be found on a single page. Pictura for multiple emblems may appear on one page with text elements of the associated emblems appearing on a subsequent page or pages.
31. Digitization provides an opportunity to provide cohesive, holistic views of emblems not available when viewing a book a single page at a time. For some uniform structured two-page emblems, this is simply a matter of re-creating book opening views of the emblems contained in the book by simply stitching together pairs of left-hand and right-hand digitized page images. For emblems that span more than two pages, or fronts and backs of individual book leaves, digitization provides an opportunity to create direct views of emblems not available in paper format. Simultaneously digitization affords us the opportunity to isolate for study views of individual emblem components, e.g., an emblem pictura. However, because of the irregularity in the structure of emblems as published, human involvement is required to identify these specialized emblem views.
.jpg)
Figure 5: Workflow to stitch together page images that comprise an emblem and to generate URL for pictura-only view of emblem
32. A Web application was created to allow project staff to easily create cohesive views of individual emblems and isolated views of picturae. Figure 5 shows the workflow implemented by this application. Figures 6 and 7 show the staff user interface for this application. Page images that comprise each emblem are identified by project staff (Figure 6) and then stitched together and saved as new Web accessible information resources by the application using a service reliant on the opensource ImageMagick software suite. Once the cohesive emblem view has been created, a project staff isolates the part of that view that is the emblem pictura (Figure 7). A persistent URL for the isolated pictura view is then minted using a local implementation of aDORe djatoka.
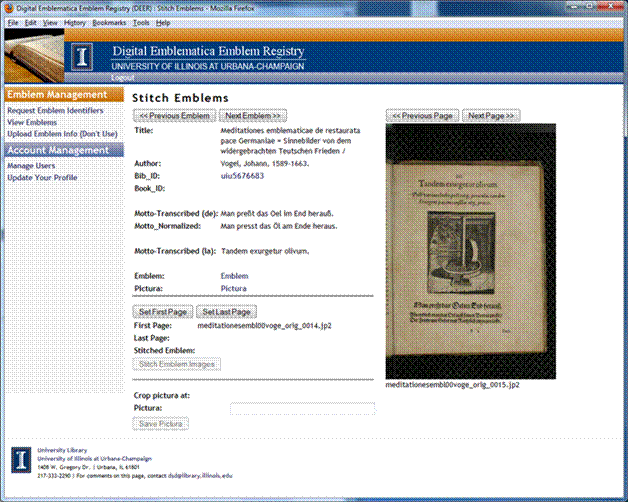
Figure 6: Interface for staff to identify page images to stitch together for emblem view
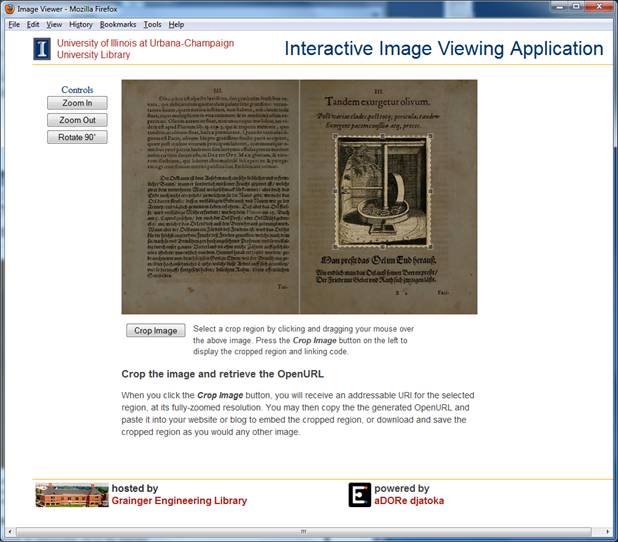
Figure 7: Application used by
staff to generate URL for isolated view of a pictura
33. Links to these newly minted resources are then added to our SPINE metadata record as XLink href attributes, and as described above Iconclass heading codes added to metadata records. The emblem and pictura view links allow scholars to see digitized views of entire emblems and of isolated views of individual pictura in a way that facilitates study of these resources. An HTML view of the end-result metadata record for a digitized emblem volume is shown in Figure 8.
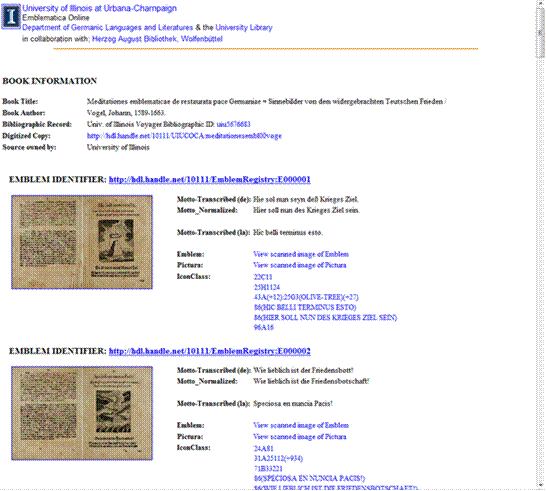
Figure 8: End-Result Book & Emblem Metadata Presented as HTML Web Page (top of page shown)
Conclusion & Next Steps
34. Having created and then enriched new SPINE metadata to describe the emblem resources we are digitizing, and having addressed identifier issues and generated additional views of digital content to facilitate use of the content, our next challenge is to provide a functional and appealing interface through which scholars can access digitized emblem resources, both at Illinois and elsewhere. By adhering to the SPINE metadata scheme and to emerging best practices of the Linked Data community, our goal is to integrate the different levels of metadata and the images created from the workflows described above into a new Emblematica Online Portal. This new portal will replace a pilot Open Emblem Portal mounted by Illinois several years ago. The new portal will be SPINE-based and will provide integrated discovery of and access to emblem-level records and instances at Illinois and HAB, and book-level and/or collection level to other major emblem collections across the world.
35. Our adoption (with HAB) of SPINE metadata will allow us to increase the functionality of the new portal. SPINE has advantages overly the previously used Dublin Core scheme. SPINE metadata is semantically rich and includes a hierarchical structure that can span granularities of description. It simultaneously holds information for an emblem book as a manifestation, information regarding the exact print item or items digitized, as well as emblem-level information such as transcribed motto and pictura Iconclass descriptions. In the new portal, scholars will be able to search both at the book level and at the emblem level. The use of manifestation-level identifiers will provide scholars with a robust and reliable way to reference emblems and their contextual objects. Over time, as reoccurrences of emblem pictura in other contexts are identified, we will be able to create proper linkages between various expressions of emblems as well as between emblem containers and context.
36. Libraries seek to improve access to content in ways that will aid scholarship and pedagogy. Digitization provides broader access to library content. With proper workflow design and adherence to emerging Web standards and best practices, digitization provides additional opportunities to facilitate broader access to resources and use of these resources at more granular levels. Though considered nuances in casual conversation, issues of provenance and citation are of major importance in scholarship and pedagogy. In translating scholarly practice to the Web, recognition of the resource and identifier definitions outlined above is essential if digitized resources are to support the needs of scholars. Accordingly, schemes like SPINE provide ways to isolate one from another the inheritable bibliographic provenance associated with the print edition of an emblem book, the ownership and other details of the copy digitized, and the manner of digitization and location of digitized instances. This in turns allows more flexibility in organization and presentation of content.
Notes
[1] http://www.germanic.illinois.edu/news/emblem/
[2] http://diglib.hab.de/rules/schema/emblem/emblem-1-2.xsd
[3] http://www.imagemagick.org/
[4] http://sourceforge.net/apps/mediawiki/djatoka/index.php
[8] CNRI Handle System < http://www.handle.net/>.
[10] http://www.fotomarburg.de/
[11] Though now considered by the W3C Technical Architecture Group largely superseded, the May 2007 draft document on dereferencing URIs provides a gentle introduction to several of these topics http://www.w3.org/2001/tag/doc/httpRange-14/2007-05-31/HttpRange-14#sec-information-resources.
[12] A full description of XLink is available in W3C’s XML Linking Language Version 1.0. http://www.w3.org/TR/xlink/
Works Cited
- Arkyves. Brandhorst, Hans. 2010. Web. 17 October 2011. <http://www.arkyves.org/>.
- Bayerische Staatsbibliothek (München)., ed. Das Verzeichnis Der Im Deutschen Sprachraum Erschienenen Drucke Des 17. Jahrhunderts: VD 17. München: BSB, 2007. Web.17 October 2011. <http://www.vd17.de/>.
- Billings, Marshall. "Digital Emblematica:The Scholarly Background of ‘Digital Emblematica’ and Its New Direction."Florilegio De Estudios Emblematicos.A Florilegium of Studies in Emblematics. Ed. Ben Rafoth. El Ferrol, A Coruña, España: Sociedad de Cultura Valle Inclán, 2004. 185-190. Print.
- Böker, Hans Josef, and Daly, Peter M., eds. The Emblem and Architecture: Studies in Applied Emblematics from the Sixteenth to the Eighteenth Centuries. Turnhout: Brepols, 1999. Print.
- Chilton, Meredith. Fired by Passion: Vienna Porcelain of Claudius Innocentius Du Paquier. Stuttgart, Germany: Arnoldsche Art, 2009: pp. 388-392. Print.
- Cool URIs for the Semantic Web. World Wide Web Consortium (W3C), 2008. Web. 17 October 2011. <http://www.w3.org/TR/cooluris/>.
- Descriptive Cataloging Of Rare Materials (books). Washington, D.C. : Cataloging Distribution Service, Library Of Congress, 2007. Print.
- Deutsches Dokumentationszentrum für Kunstgeschichte - Bildarchiv Foto Marburg. Philipps Universität Marburg,. 2010. Web, 17 October 2011. <http://www.fotomarburg.de/>.
- Graham, David. “Three Phases of Emblem Digitization: the First Twenty Years, the Next Five.” Digital Collections and the Management of Knowledge: Renaissance Emblem Literature as a Case Study for the Digitization of Rare Texts and Images. Ed. Mara R. Wade. Salzburg: DigiCULT, 2004. 13-18. Print.
- Handle System. Corporation for National Research Initiatives, 2010. Web. 17 October 2011. <http://www.handle.net/>.
- Iconclass. Netherlands Institute for Art History, 2006. Web. 17 October 2011. <http://www.iconclass.nl/>.
- IFLA Study Group on the Functional Requirements for Bibliographic Records. Functional Requirements for Bibliographic Records. LK Den Haag, Netherlands: The International Federation of Library Association, 2007. Web. 17 October 2011. <http://archive.ifla.org/VII/s13/frbr/frbr_current_toc.htm>.
- Landwehr, John. French, Italian, Spanish, and Portuguese Books of Devices and Emblems 1534-1827: A Bibliography. Utrecht: Haentjens, Dekker & Gumbert, 1976. Print.
- Linked Data - Connect Distributed Data Across the Web. Linked Data community, 2010. Web. 17 October 2011. <http://linkeddata.org/>.
- LINKINGOPENDATA. World Wide Web Consortium (W3C), 2010. Web. 17 October 2011. <http://esw.w3.org/SweoIG/TaskForces/CommunityProjects/LinkingOpenData>.
- Nash, Frederick N., and Thomas McGeary, eds. Emblem books at the University of Illinois: A Bibliographic Catalogue. Boston, Mass: G.K. Hall, 1993. Print.
- Rawles, Stephen. "A SPINE of Information Headings for Emblem-Related Electronic Resources." Digital Collections and the Management of Knowledge: Renaissance Emblem Literature as a Case Study for the Digitization of Rare Texts and Images. Ed. Mara R. Wade. Salzburg: DigiCULT, 2004. 19-28. Print.
- Thomas, Stäcker. "Transporting Emblem Metadata with OAI." Digital Collections and the Management of Knowledge: Renaissance Emblem Literature as a Case Study for the Digitization of Rare Texts and Images. Ed. Mara R. Wade. Salzburg: DigiCULT, 2004. 89-96. Print.
- W3C Semantic Web. World Wide Web Consortium (W3C), 2010. Web. 17 October 2011. <http://www.w3.org/2001/sw/>.
- XML Linking Language (XLink) Version 1.0. World Wide Web Consortium (W3C), 2001. Web. 17 October 2011. <http://www.w3.org/TR/xlink/>.
Responses to this piece intended for the Readers' Forum may be sent to the Editors at M.Steggle@shu.ac.uk.
![]()
© 2012-, Matthew Steggle and Annaliese Connolly (Editors, EMLS).